作者序
本文所谈的绝大部分内容在众多文章中都有讲到,再复述一遍并非本意。本文的目的是了解各种工具、定量分析网络状态;当遇到网络性能问题的时候,根据原理和出现的可能性,有的放矢。
MSS vs MTU 有什么区别?
发送窗口 vs 接收窗口 vs 拥塞窗口 ?
RTT & RTO 是什么含义
哪些常见的工具可以探查网络状态?
如何定量分析延迟、吞吐等性能问题?
其他说明:
文中 Wireshark 相关的使用,来源于 《Wireshark 网络分析就这么简单》、《Wireshark 网络分析的艺术》

应用程序发送到协议栈的数据长度是由应用程序本身决定的。不同的应用程序有不同的实现方式,有些应用程序一次性发送所有数据,而有些应用程序则会逐字节或逐行发送数据。最终,发送到协议栈的数据量由应用程序决定,协议栈无法控制这种行为。
如果协议栈一接收到数据就立即发送,可能会发送大量的小数据包,导致网络效率降低。因此,需要在累积一定数量的数据后再发送。但是,累积多少数据才能发送取决于操作系统的种类和版本。
现在,假设有一个需要写入的操作比较大,例如 4000 字节,那么 TCP 层会如何处理呢?是否只需添加 TCP 标头并将其发送到网络层呢?
答案是否定的。因为网络对数据包大小有限制,最大传输单元(MTU,Maximum transmission unit)指的是网络可以传输的最大数据包大小。大多数网络的 MTU 为 1500 字节,这意味着 4000 字节的数据包要么会被丢弃,要么会被分片。如果数据包被丢弃,传输将彻底失败。如果数据包被分片,将会导致传输效率降低。

那被切分的包又该怎么重组呢?
仍然以一个数据包大小为 4000 字节,MTU 为 1500 字节为例,当发送端的 IP 层将该数据包发送到网络层时,会检查数据包大小是否超过 MTU 限制。
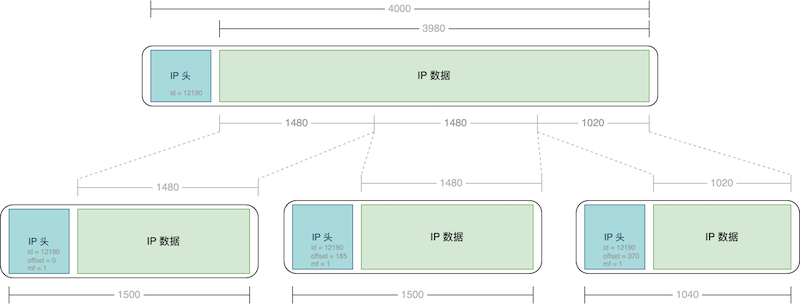
如果超过了,IP 层会将该数据包分成三个分片,分别是:
第一个分片,偏移量为 0,大小为 1500 字节;
第二个分片,偏移量为 1480(前一个分片占去了 20 字节的 IP 头部空间),大小为 1500 字节;
第三个分片,偏移量为 2960(前两个分片占去了 2960 字节的空间),大小为 1020 字节。
分片的重组需要依据 IP Header 中的标识(Identification)和标志(Flags)字段来完成。标识字段用于标识分片属于哪个数据报,而标志字段用于标识分片是否允许再分片和是否为最后一片。具体而言,同一个数据报的所有分片都应该具有相同的标识字段值,而 DF(Don’t Fragment,不分片)和 MF(More Fragments,还有更多分片)标志则用于标识分片是否允许再分片和是否为最后一片。
在接收端,当接收到这些分片时,它们会根据标识字段进行分类。如果一个数据报的所有分片都到达了接收端,那么接收端就可以使用偏移量和分片大小将这些分片按正确的顺序重新组装成原始数据包。如果某个分片没有到达接收端,那么接收端会等待一段时间,如果超时后仍然没有收到该分片,那么接收端就会向发送端发送一个请求重传的消息。
假设客户端和服务器的 MTU 大小分别为 1500 和 1200 字节。在这种情况下,客户端最大能发出多少字节的包呢?
根据上面的结论,发包的大小是由 MTU 较小的一方决定的,因此客户端最大只能发送 1200 字节的包。如果客户端尝试发送 1500 字节的包,那么这个包将被分片成两个部分,每个部分的大小分别为 1200 字节和 300 字节。如果 DF 标志位设置为 1,表示不允许分片,因此这个数据包会则会被丢弃,传输失败。
每个 IP 包都有一个 TTL 字段,表示该包的生存时间。每当一个 IP 包经过一个路由器,TTL 字段就会减 1,当 TTL 为 0 时,该包就会被丢弃。根据 TTL 的特性,只需翻出网络拓扑图,就能大概知道该包是哪台设备发出。
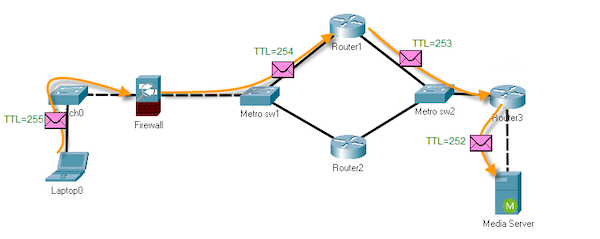
除此之外,TTL 还可以用于检测网络劫持和请求延迟问题。如果我们怀疑网络连接被劫持,可以通过检查 TTL 值来确定是否存在额外的跳数。而如果请求延迟较高,也可以通过检查 TTL 值来确定是否存在较远的跳数,从而进一步分析网络瓶颈所在。

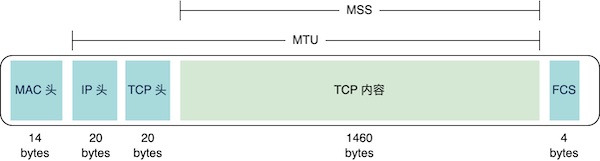
由于 IP 层 MTU 的存在,TCP 协议需要控制 MTU,从而避免数据过大而需要分包传输的问题,提高网络传输效率。
在 TCP 连接建立过程中,客户端和服务器会互相通告各自的 MSS(Maximum Segment Size,最大分段大小),MSS 是指 TCP 数据段中数据部分的最大长度。MSS 加上 TCP 头和 IP 头的长度,就是双方可以承载的最大 MTU。
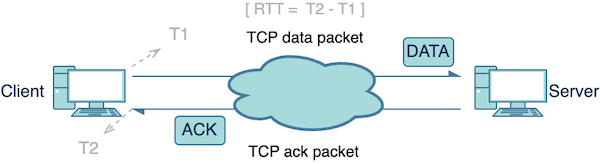
RTT(往返时延)是指从发送方发送数据到发送方接收到来自接收方的确认消息所经过的时间。在网络通信中,RTT 时延不仅与链路的传播时间有关,还包括路由器等网络中间节点的缓存和排队时间,以及末端系统的处理时间。
尽管在同一条链路上,报文的传输时间和应用处理时间相对固定,但网络设备和末端系统的网络拥堵情况下,排队时间的增加会导致 RTT 时延波动。
此外,流量负载均衡的存在会导致选择的传输路径和经过的网络设备不同,即使是同一个上下游服务的请求,也会出现 RTT 时延的差异。
MTR(My Traceroute)是一种网络诊断工具,可以通过在连续的时间间隔内将网络节点的 traceroute(跟踪路由)操作的结果显示在同一屏幕上,从而提供更详细的网络信息。
使用 MTR 可以帮助我们了解数据包在网络中的路径和每个跃点的 RTT,从而更方便地定位网络问题。例如,如果我们发现某些数据包延迟较高,我们可以使用 MTR 查看这些数据包的路径和每个跃点的 RTT,以确定延迟出现的具体位置。此外,MTR 还可以通过连续的监测,提供有关网络稳定性和性能的有用信息,从而帮助我们优化网络性能
在我们日常生活中,排队和拥挤现象时常发生,如医院看病、邮局等候服务等。除了实际排队之外,还有一种无形的排队,即网络拥堵导致的网速变慢。
为了减少排队现象,增加服务窗口是一个可行的解决方案,但这也会增加服务成本。反之,缩小服务窗口可以提高窗口的利用率,降低成本,但会增加用户排队等待的时间。这两者是相互矛盾的。
为了在保证用户满意度(响应时间)的前提下,最大限度地挖掘系统潜力、提高利用率(控制成本),TCP 通过窗口(发送窗口/拥塞窗口)大小来实现这一目标。
由于无法确认接收方是否能及时接收数据包,TCP 传输中不适合每发一个数据包就停下来等待确认,因为这样传输效率太低。最好的方式是一次性将所有数据包发送出去,然后一起等待确认。但是,实际情况存在一些限制:
接收方的缓存(接收窗口)可能无法一次性接收所有数据;
网络的带宽也不一定足够大,一次性发送过多的数据包可能导致数据丢失。
因此,在 TCP 传输中,发送窗口通过限制发送数据包的数量来平衡传输效率和数据可靠性。发送窗口的大小计算公式为 wnd = min(rwnd, cwnd * mss),其中 rwnd 表示接收方告知的接收窗口大小,cwnd 表示发送方的拥塞窗口大小。在此限制范围内,尽可能多地发送数据包,一次可以发送的数据量即为 TCP 发送窗口。
发送窗口大小对传输性能的影响非常大。下图显示了发送窗口大小为 1 个 MSS(即每个 TCP 包所能携带的最大数据量)和 2 个 MSS 时的差别。在相同的往返时间内,发送窗口大小为 2 个 MSS 时,传输的数据量是发送窗口大小为 1 个 MSS 的两倍。
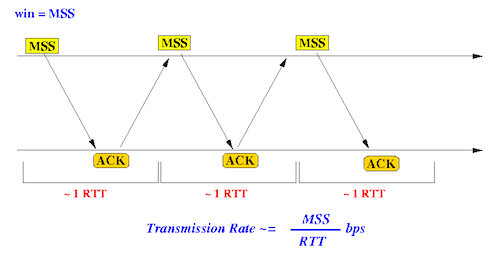
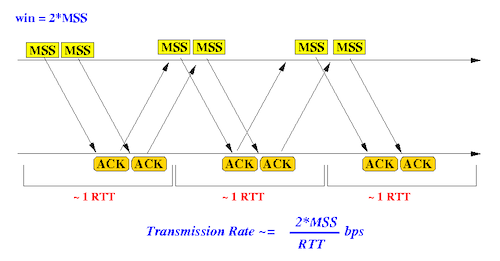
在实际应用中,发送窗口通常可以达到数十个 MSS 的大小,因此发送窗口的大小会对 TCP 传输的效率和可靠性产生巨大影响。
发送窗口 VS MSS
发送窗口决定了一口气能发多少字节,而 MSS 决定了这些字节要分多少个包发完。例如:
发送窗口为 16000 字节,MSS 为 1000 字节时,需要发送 16000/1000=16 个包;而如果 MSS 等于 8000,那要发送的包数就是 16000/8000=2。
在 TCP 协议中,接收窗口是一项非常重要的参数,它决定了发送方在一个确定时间内可以发送多少数据。
在 TCP 协议初期,网络带宽非常有限,因此 TCP 的最大接收窗口被定义为 65535 字节。但随着网络带宽的提高,这个值已经无法满足现代网络传输的需求了。
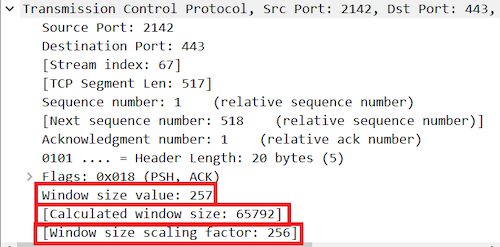
如果抓包时没有抓到三次握手,Wireshark 就不知道该如何计算,所以有时候会很莫名地看到一些极小的接收窗口值。
如果防火墙识别不了 Window Scale,因此对方无法获得 Shift count,最终导致严重的性能问题。
1992 年,RFC 1323 提出了一种解决方案,即在三次握手时向对方发送自己的 Window Scaling 信息,Window Scaling 是一个 2 的指数,通过它可以计算出实际的 TCP 接收窗口大小。这个方案的好处是可以不需要修改 TCP 头的设计。
# 查看 Linux 内核 TCP Window Scalingsysctl net.ipv4.tcp_window_scaling > net.ipv4.tcp_window_scaling = 1# 设置 Linux 内核 TCP Window Scalingsudo sysctl -w net.ipv4.tcp_window_scaling=0 > net.ipv4.tcp_window_scaling = 0
拥塞控制的基本思想是发送方通过维护一个虚拟的拥塞窗口,控制数据包的发送速度,以防止网络拥塞。
在连接建立初期,发送方对网络状况一无所知。由于一次发送过多数据可能会遭遇拥塞,因此发送方需要将拥塞窗口的初始值设置得很小。根据 RFC(请求评论文档)的建议,初始值为 2 个、3 个或者 4 个 MSS(最大报文段长度),具体取决于 MSS 的大小。
在慢启动过程中,拥塞窗口大小随着时间的推移而逐渐增加。此时,传输速度比较快,触碰拥塞点的风险也增加。因此,不能继续采用翻倍的慢启动算法,而是要缓慢增加拥塞窗口大小。根据 RFC 的建议,在每个往返时间中增加 1 个 MSS。例如,如果发送了 16 个 MSS 并得到全部确认,则拥塞窗口大小增加到 16+1=17 个 MSS。随后,拥塞窗口大小会增加到 18、19 等,这个过程称为拥塞避免。
在慢启动过渡到拥塞避免的临界窗口值方面,需要根据之前是否发生过拥塞来确定。如果发生过拥塞,则应将该拥塞点作为参考。如果从未发生过拥塞,则可以选择一个较大的值,例如与最大接收窗口相等。
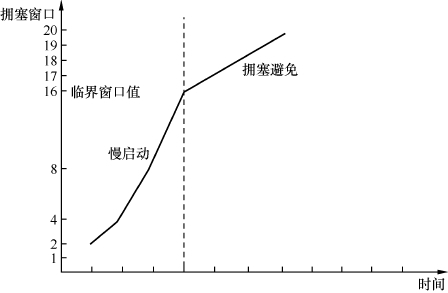
具体怎么知道窗口多大会触发拥塞呢?
假设我们要计算的是某个 TCP 连接的拥塞点,而在该连接中存在一连串重传包。首先,我们需要找到重传包序列中的第一个包,然后根据其 Seq 值找到其对应的原始包,进而计算出原始包发送时刻的在途字节数。因为网络拥塞发生在该原始包发送的时刻,因此该时刻的在途字节数大致代表了拥塞点的大小。
在途字节数的计算公式应该是:
在途字节数 = Seq + Len - Ack
其中,Seq 是指包的序列号,Len 是包的长度,Ack 是指确认号。
具体步骤:
Wireshark 上单击 Analyze 菜单,再单击 Expert Info 选项,得到重传统计表。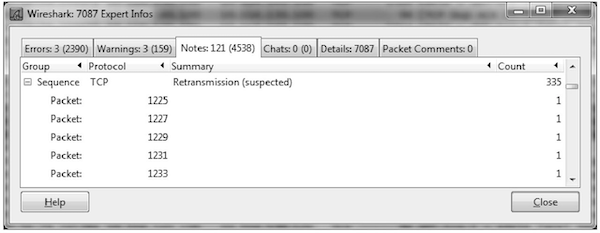
点击第一个重传包No.1225,可见它的 Seq=1012852。于是用“tcp.seq ==1012852”作为过滤条件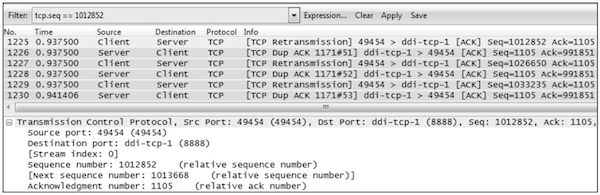
点击 Apply 过滤之后得到了原始包 No. 1053
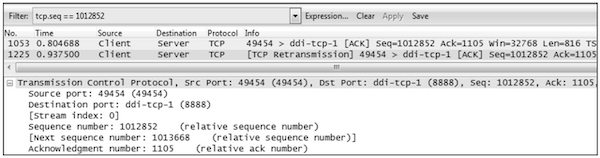
选定 1053 号包,然后点击 Clear 清除过滤。可见上一个来自服务器端的包是 1051 号包
利用上述公式,可知当时的在途字节数为 1012852(No.1053 的 Seq)+816(No.1053 的 Len)-910546(No.1051 的 Ack)=103122 字节。
在传输数据时,由于网络拥塞、硬件故障等原因导致数据包未能及时到达接收方,发送方会重新发送该数据包。
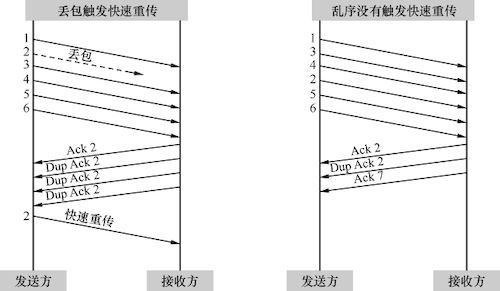
在网络传输过程中,丢包是很常见的问题,不过有时候出现的丢包症状并不像严重拥塞时那么明显。一些因素如校验码不对可能导致单个包的丢失,或者只有少量的包丢失。当这些包的后续包能够正常到达接收方时,接收方会发现其 Seq 号比期望的大,为了提醒发送方重传这些包,接收方会每收到一个包就 Ack 一次期望的 Seq 号。当发送方接收到三个或以上的重复确认(Dup Ack)时,发送方便会意识到相应的包已经丢失,于是立即重传它。这个过程称为快速重传,与超时重传不同,它无需等待一段时间。
为什么要规定收到 3 个或以上的重复确认才会重传呢?这是因为网络包有时会乱序,乱序的包同样会触发重复的 Ack,但是为了乱序而重传却是不必要的。因为一般乱序的距离不会相差太大,比如 2 号包也许会跑到 4 号包后面,但不太可能跑到 6 号包后面。所以规定收到三个或以上的重复确认,可以在很大程度上避免因乱序而触发快速重传。
如下图所示,2 号包的丢失凑满了 3 个 Dup Ack,所以触发快速重传。而在右图中,2 号包跑到 4 号包后面,但因为凑不满 3 个 Ack,所以没有触发快速重传。
如果在拥塞避免阶段发生了快速重传,是否需要像发生超时重传一样处理拥塞窗口呢?
其实并没有必要。因为如果后续的包都能正常到达,那么说明网络并没有严重拥塞,只需要在接下来传输数据时减缓一些速度即可。
RFC 5681 规定,在发生拥塞时还没被确认的数据量的 1/2(但不能小于 2 个 MSS)设为临界窗口值。然后将拥塞窗口设置为临界窗口值加 3 个 MSS,继续保留在拥塞避免阶段。这个过程被称为快速恢复,其拥塞窗口的变化可以用下图表示:
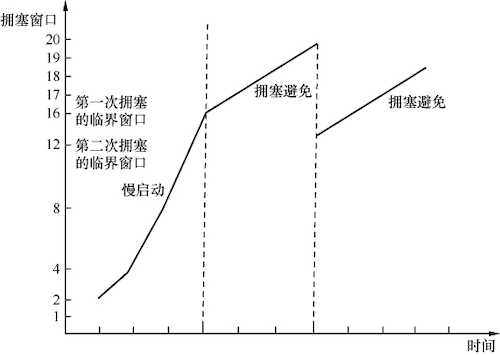
在网络中,发生拥塞后会影响到发送方,因为发送方发送的数据包可能无法像往常一样得到及时的确认。当无法收到确认时,发送方会等待一段时间来判断是否存在网络延迟。如果超过了一定时间仍然没有收到确认,发送方就会认为这些数据包已经丢失,只能通过重传来保证数据的正确性。这个过程被称为超时重传,而从发送原始数据包到重传该数据包的这段时间被称为 RTO。
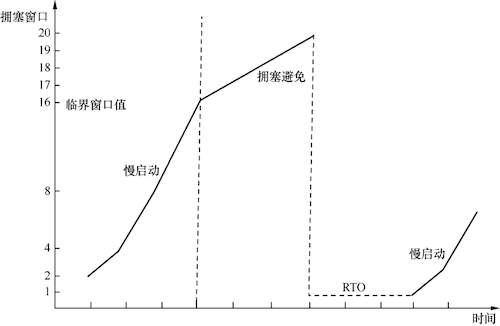
在 Linux 内核编译时,RTO 的最小值就已被确定,默认值为:200 ms
#define TCP_RTO_MAX ((unsigned)(120*HZ))#define TCP_RTO_MIN ((unsigned)(HZ/5))
然而,超时重传对传输性能有严重的影响。
首先,发送方在等待 RTO 的过程中不能传输数据,相当于浪费了一段时间。
其次,拥塞窗口会急剧减小,这将导致接下来的传输速度变慢。
即使是一次万分之一的超时重传,也可能对传输性能产生不可忽视的影响。
如何检查重传情况呢?
Wireshark 单击 Analyze–>Expert Info Composite 菜单,就能在 Notes 标签看到它们了,如图所示。点开 + 号还能看到具体是哪些包发生了重传。
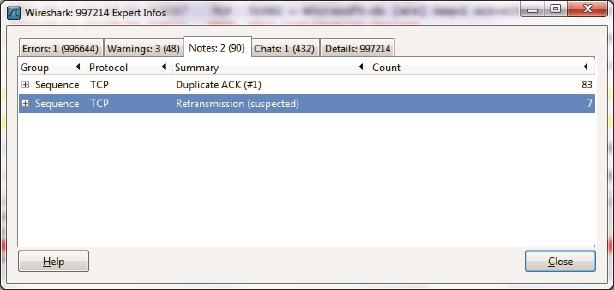
从 Notes 标签中看到 Seq 号为 1458613 的包发生了超时重传。于是用该 Seq 号过滤出原始包和重传包(只有在发送方抓的包才看得到原始包),发现 RTO 竟长达 1 秒钟以上。这对性能的影响实在太大了。找出瓶颈彻底消除重传之后:

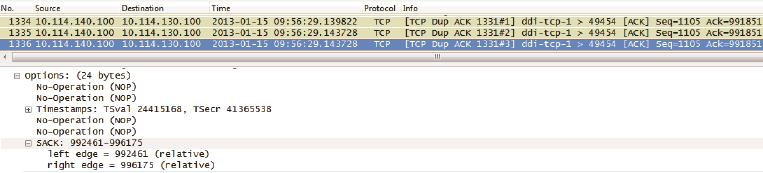
SACK(Selective Acknowledgment 选择性确认)是一种重传机制,其可以向发送方发送接收状态信息。通过 SACK,发送方可以准确地知道哪些数据包已经被接收,哪些数据包还未接收到,从而只需要重传丢失的数据包。
在真实环境中,我们可以抓取到 SACK 的实例。结合“Ack = 991851”和“SACK = 992461-996175”这两个条件,发送方可以知道 992461-996175 的数据已经被接收,而 991851-992460 的数据则还未被接收。这为重传丢失的数据包提供了有力的指引。
除了众所周知的算法外,Linux 内核还提供了多个 TCP 拥塞控制算法,这些算法具有不同的传输特性,可以在 TCP 传输的重要指标,如往返传输时延(RTT)和吞吐量方面表现出不同的效果,包括:Reno、Cubic、BIC、Westwood+、Highspeed、Hybla 等。
# 查询支持的TCP拥塞控制算法sysctl net.ipv4.tcp_available_congestion_control > net.ipv4.tcp_available_congestion_control = reno cubic bbr# 查询应用的TCP拥塞控制算法sysctl net.ipv4.tcp_congestion_control > sysctl net.ipv4.tcp_congestion_control
在实际应用中,我们可以根据具体需求和网络环境选择合适的 TCP 拥塞控制算法,以达到最佳的网络传输效果。
为了保证数据的可靠性,它使用了流量控制、拥塞控制、确认机制等多种技术,这些技术都需要消耗网络带宽和处理资源。
当发送端发送的数据包大小过小时,就会导致网络中出现大量的TCP头部、IP头部等固定长度的协议头。因为一个 TCP 包的头部和 IP 头部至少会占用 40 个字节的空间,而携带的数据很小时就像快递员开着大货车去送小包裹一样浪费。
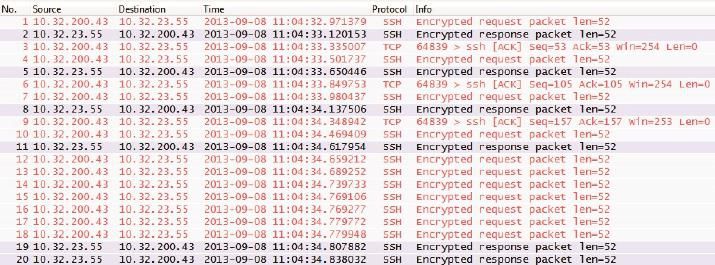
协议头会占用大量的网络带宽和处理资源,从而导致网络传输效率下降。为了避免TCP小包问题,发送端可以使用一些方法来增加数据包的大小,比如使用 Nagle算法、延迟确认。
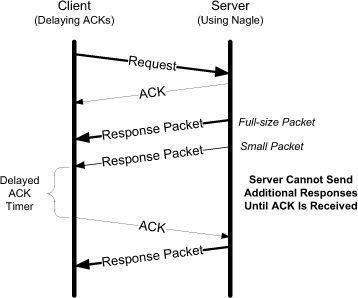
Nagle 算法的原理是在发出去的数据还没有被确认之前,如果有小数据生成,就先把这些小数据收集起来,凑满一个最大报文段长度(MSS)再进行发送。这样可以减少网络中的小数据包,提高网络的利用率。
延迟确认的原理是这样的:如果接收方收到一个数据包后没有需要立即回复的数据要发送给发送方,那么它就会延迟一段时间再发送确认信息。如果在这段时间内有需要发送的数据,那么确认信息和数据就可以在同一个数据包中一起发送出去。
当与 Nagle 算法同时启用时,延迟确认可能会导致性能下降
理解 TCP 协议的机制和字段含义,是为了当传输性能问题发生时,更好地应用它。
当出现延迟问题时:
延迟指标 = 新建连接耗时 + RTT + (Retransmission + RTO) + (Fast Retransmission + Dup ACK) + Retransmission(Out-Of-Order) - SACK + Delay ACK + Nagle Algorithm
首先,应查看连接状态(是否频繁新建连接)及 RTT 情况
其次,关注是否有重传,是那种类型的重传,以及 SACK 是否有开启
最后,确认延迟确认和 Nagle 算法对延迟的影响
类似的,当出现吞吐问题时:
吞吐指标 = (总耗时 - (新建连接耗时 + 重传耗时 + RTO 耗时))/ RTT * MSS * (Cwnd / MSS) - Retransmission
首先,应查看连接状态(是否频繁新建连接)、RTT 情况
其次,关注是否有重传,是哪种类型的重传
最后,确认窗口大小、MSS 等值的状态
